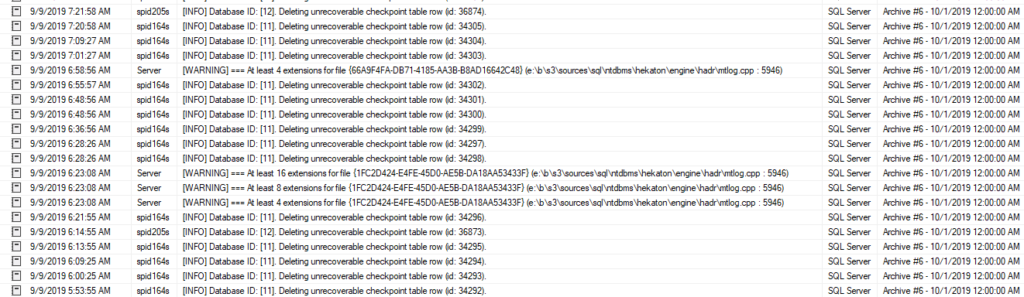
You probably have tons of these things filling up your logs. They are completely normal and refer to SQL’s process of cleaning up the list of checkpoints that the In-Memory process uses to provide data consistency and durability. Paul Randall answered a question about these messages in his SQL Skills Insiders Newsletter (PDF link).
It’s nice that they are labeled with [INFO], so you can be fairly sure they aren’t a major issue, but they still annoyingly fill up the log with information that is of no use to anyone outside of Microsoft. It would be nice if you could disable these messages but, to my knowledge, you cannot.
Occasionally, you may see another message in your error log, one that seems like it might be more serious:
[WARNING] === At least 4 extensions for file {0BAE5D9C-35C2-480C-BE9C-7D2AFEEE4EA0} (e:\b\s3\sources\sql\ntdbms\hekaton\engine\hadr\mtlog.cpp : 5946)
This one is identified as a [WARNING]. Uh-oh! That can’t be good.
From the path and filename, it pretty clear this message is also related to logging for in-memory tables, but how? Despite my efforts, I was unable to find out much about this message online. I did find one post from someone at Microsoft saying they would investigate the warning, but there was never any follow up.
Was this something I should be concerned about? Given that my system had been running fine for months and months, my thought was it was probably unimportant and could be ignored. Still, I’d like to know what it meant.
When my internet sleuthing didn’t turn up any answers, I contacted the folks at SQL Skills and Erin Stellato was kind enough to ask her contacts at Microsoft.
Bottom line: it can be ignored.
The message is simply stating that the log file has been extended, i.e. grown in size. It reports at power of 2 intervals.
I have no idea why this is labelled WARNING, as opposed to INFO, like the other message. It would also be nice if these informational-only messages were not written to the error log, or at least written at a much lower frequency. Literally 85% of my error log are just these two messages! Perhaps in SQL 2019, these messages aren’t logged….
I hope that by putting this out there, someone else who might be bothered by this warning can relax a bit.
I ran into an interesting case today. We’ve got a pair of SQL Servers running in an Availability Group. We’re set up so we can run with either server as the primary. We use Sentry One to monitor our SQL servers and after a recent planned failover, I noticed that when we run on Server 1, CPU processor utilization seems to be lower than when we are running on Server 2. Not drastically lower and there is not enough difference that our users would complain about it, but when I looked at the graphs, I could definitely see a difference.
This bothered me. The two servers have identical hardware and SQL Server is configured identically on both. I ran through all the checks I could think of: power management was set to High Performance on both, NIC drivers were the same version, both were using the same SAN and local drives for storage, memory was the same, anti-virus settings were identical. I just couldn’t explain why Server 1 was always running with about a 10% lower CPU utilization.
Server 1 on the left, Server 2 on the right
Normally, I like seeing a low CPU utilization. I like my SQL Servers to have some headroom to handle an increase in load. We had been running on Server 1 for a long time in the past and, looking at the CPU utilization, I thought we had lots of room to handle an increased load. But when we were running on Server 2, I wasn’t so sure.
One morning, I decided to dig a little deeper. I had already confirmed Windows power management was set to High Performance on both servers. However, this time, I dug a little deeper and checked out what those settings actually were. Turns out, that was where the difference was.
I discovered that Server 2 was set to a maximum processor state of 100%, but Server 1 was set to 75%. Aha! That was the reason Server 1 always had a lower CPU utilization! Windows was limiting processor use to 75%!
Digging deeper still, I found several other settings that were different: minimum processor state, hard drive shutoff time, PCI Express link state power management, and one or two others.
The moral is just because your CPU utilization looks low, make sure that it isn’t because there is some other rule limiting your processor utilization!
I was doing some investigating the other day and trying to find which tables in our environment were the most written to. This was because my buddies in the IT department had gotten a bunch of new storage that was optimized for a write-intensive workload. To identify which tables had the most writes, I used the following query:
DECLARE @dbid INT = DB_ID();
SELECT TableName = OBJECT_NAME(s.object_id),
Reads = SUM(user_seeks + user_scans + user_lookups),
Writes = SUM(user_updates)
FROM sys.dm_db_index_usage_stats AS s
INNER JOIN sys.indexes AS i
ON s.object_id = i.object_id
AND i.index_id = s.index_id
WHERE OBJECTPROPERTY(s.object_id, 'IsUserTable') = 1
AND s.database_id = @dbid
GROUP BY OBJECT_NAME(s.object_id)
ORDER BY Writes DESC;
GO
This pulls both reads and writes from the sys.dm_db_index_usage_stats dynamic management view. A read is defined as either a seek, scan, or lookup and a write is defined as an update. All seemed good until I noticed something strange. One of the top written to tables was, based on our naming convention, a lookup table. That seemed odd. A lookup table should have lots of reads, but only few writes. The query above showed my lookup table had almost twice as many writes as reads!
I dug around a bit and found two stored procedures that referenced that particular table. I checked them out, but nothing seemed out of the ordinary to me, so I dug a little deeper and discovered something strange: the user_updates value of sys.dm_db_index_usage_stats can get incremented even when there is no actual update to the table!!
Let’s check it out. First, create a table. I’m going to go with a lookup table, as that’s what I was dealing with. It’s a simple table – one identity column and one varchar column for a machine name.
Now let’s insert a couple rows of data to work with:
INSERT INTO Lkp_Machine
(
MachineName
)
VALUES
('Machine01'),
('Machine02'),
('Machine03');
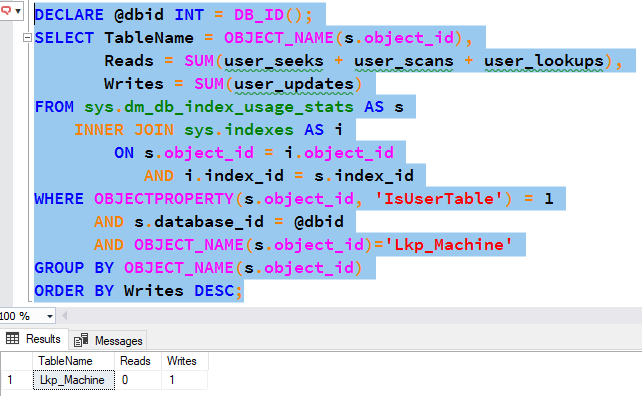
Finally, let’s see what our DMV reports: (I’ve modified it slightly to only show our table.)
DECLARE @dbid INT = DB_ID();
SELECT TableName = OBJECT_NAME(s.object_id),
Reads = SUM(user_seeks + user_scans + user_lookups),
Writes = SUM(user_updates)
FROM sys.dm_db_index_usage_stats AS s
INNER JOIN sys.indexes AS i
ON s.object_id = i.object_id
AND i.index_id = s.index_id
WHERE OBJECTPROPERTY(s.object_id, 'IsUserTable') = 1
AND s.database_id = @dbid
AND OBJECT_NAME(s.object_id)='Lkp_Machine'
GROUP BY OBJECT_NAME(s.object_id)
ORDER BY Writes DESC;
GO
Here’s the output:
OK. We inserted 3 rows, but got a write count of 1. That’s normal. Books Online says of the user_updates field: “Number of updates by user queries. This includes Insert, Delete, and Updates representing number of operations done not the actual rows affected. For example, if you delete 1000 rows in one statement, this count increments by 1”
Doesn’t really explain my situation though. It did, however, give me an idea. I decided to do another test using this code:
DECLARE @TestVariable CHAR(1);
UPDATE Lkp_Machine
SET @TestVariable = 'a';
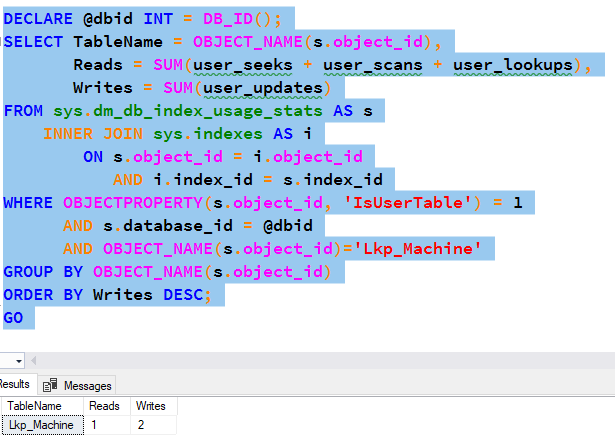
This query does not actually update the table. It simply sets a variable. Now when we run the write count query again, what do we get?
Look at that! We got one read and one more write! The user_updates count was incremented even though there was no actual update to the table.
It would seem this DMV increments the update count whenever the table is referenced in an update command.
Why would someone do this? I admit, my test query is somewhat silly. However, you may very well encounter this situation disguised as a MERGE statement. This was where I found it.
Our developers wanted to check the lookup table for the existence of a certain machine name. If that name did not exist, they wanted to insert it into the table and get the id that was created for it, but if it did exist, they only needed to get the id value of that machine. Here is their code:
MERGE Lkp_Machine AS A
USING
(SELECT @machineName AS machineName) AS B
ON B.machineName = A.MachineName
WHEN MATCHED THEN
UPDATE SET @idMachine = A.idMachine
WHEN NOT MATCHED THEN
INSERT
(
machineName
)
VALUES
(B.machineName)
OUTPUT Inserted.idMachine
INTO @inserts;
The syntax of the MERGE statement requires that the command after the WHEN MATCHED clause be either an UPDATE or a DELETE. We don’t really need to update the table here – we just want to set a variable – but the syntax forces the UPDATE command.
Granted, this probably isn’t the best way to perform this action. However, it is how this particular developer coded it and it’s what I, as the DBA, have to live with. Just be aware that some of your tables might not actually be getting updated as often as this DMV implies!
Have you ever had random inserts into a large table fail? Most of the time, inserts happen fine, but every so often you get a failure with a “primary key violation” error? If your primary key is an integer column with the identity property, you may be wondering how this is possible.
What is likely happening is your table has grown very large or has been in use for a long time and your identity column ran out of numbers. An integer column has a maximum value of 2,147,483,647. Now an integer can start at -2,147,483,648, but most people start at 0 or 1, so that leaves you with 2 billion numbers.
The first time this happens, someone (maybe you) will reseed the identity column to a new value (zero, in this case):
DBCC CHECKIDENT (YourTable,RESEED,0)
If your table has a lot of records that have been deleted, you might be able to continue on for quite some time before encountering another primary key violation. But this is not a permanent fix – you will encounter this error again eventually.
Another temporary fix, but one that will likely allow you to go for a longer time without encountering the primary key violation again is to reseed the column to the smallest negative number the datatype allows (assuming you have a positively incrementing identity value). For example, to reseed an integer column, you can run:
DBCC CHECKIDENT (YourTable,RESEED,-2147483647)
Assuming you started at zero or 1, this gives you another 2 billion values to use. However, I’ve found most programmers, for some reason, have an aversion to negative numbers as primary keys. There no reason for it, but it’s there, so the DBA has to deal with it.
Of course, the permament fix is to change the data type from integer to BIGINT, but, if your table is big enough to have this problem, that will also present its own set of challenges – this is a “size of data” operation, meaning SQL has to modify every single row in the table and the time it takes to do this is directly related to the size of the data in the table. The change will require the table to be locked, lots of transaction log will be generated, etc. See Kendra Little’s post about the issues you will face here.
The path of least resistance (and least (or no) downtime) is to reseed the identity column. This is virtually instantaneous. The problem becomes “to what value should I reseed it?”
To answer this question, you need to know where the gaps in your used identity values are. Ideally, you’ll like to reseed to the start of the biggest gap.
I went searching for some code to do this and came across this solution from Microsoft:
-- Use a recursive CTE approach, which will provide
-- all values in all gap ranges
DECLARE @i INT;
SELECT @i = MAX(PK_ID)
FROM YourTable;
WITH tmp (gapId)
AS (SELECT DISTINCT
a.PK_ID + 1
FROM YourTable a
WHERE NOT EXISTS
(
SELECT * FROM YourTable b WHERE b.PK_ID = a.PK_ID + 1
)
AND a.PK_ID < @i
UNION ALL
SELECT a.gapId + 1
FROM tmp a
WHERE NOT EXISTS
(
SELECT * FROM YourTable b WHERE b.PK_ID = a.gapId + 1
)
AND a.gapId < @i)
SELECT gapId
FROM tmp
ORDER BY gapId;
GO
However, when I ran this, I got the following error:
Looks like my table has too many gaps for this to be a valid solution. So back to Google I went and found this really nice solution from Henning Frettem. When I ran his code, I saw my table had 97,236 gaps! So which should I use? Ideally, the largest one! Henning’s code didn’t readily give that, so below is my modified version which gives you that information and sorts from the largest gap to the smallest, since the largest gap is what you are really looking for.
;WITH cte
AS (SELECT PK_ID, /* replace with your identity column */
RowNum = ROW_NUMBER() OVER (ORDER BY PK_ID)
FROM dbo.YourTable), /* replace with your table name */
cte2
AS (SELECT cte.PK_ID,
cte.RowNum,
DENSE_RANK() OVER (ORDER BY PK_ID - RowNum) AS Series /* replace with your identity column */
FROM cte),
cte3
AS (SELECT cte2.PK_ID,
cte2.RowNum,
cte2.Series,
COUNT(*) OVER (PARTITION BY Series) AS SCount
FROM cte2),
cte4
AS (SELECT MinID = MIN(PK_ID), /* replace with your identity column */
MaxID = MAX(PK_ID), /* replace with your identity column */
Series
FROM cte3
GROUP BY Series)
SELECT GapStart = a.MaxID,
GapEnd = b.MinID,
SizeOfGap = b.MinID - a.MaxID
FROM cte4 a
INNER JOIN cte4 b
ON a.Series + 1 = b.Series
--ORDER BY GapStart
ORDER BY ABS(b.MinID - a.MaxID) DESC;
In the output screenshot below, I had already reseeded my table to the smallest integer value, so that’s why you see that first big 2 billion row gap. In my case, someone had already reseeded the table to negative numbers in the past, so my developers were OK with using negative numbers.
If you encounter this problem and are unable to change the datatype, you now have the code to find the largest gap to use when reseeding your identity value!
My company recently purchased SQL Sentry (oops, they changed the name to Sentry One over two years ago, although the website still says SQL Sentry all over the place) and I’ve been spending the last several weeks setting it up and configuring all the alerts. There are a ton of items it monitors and, while the default thresholds are good, they definitely need tweaking to fit your environment. Unless you enjoy getting thousands of email alerts, that is.
I’ve finally gotten those alerts down to a manageable number and I can start paying attention to them. One alert caught my eye because it was one I hadn’t seen before. I was getting these errors in the Windows Application log:
Someone made SQL beg. “Please simplify the query. Please!” Don’t grovel, SQL. You’re better than that.
The query processor ran out of internal resources and could not produce a query plan. This is a rare event and only expected for extremely complex queries or queries that reference a very large number of tables or partitions. Please simplify the query. If you believe you have received this message in error, contact Customer Support Services for more information.
Rare, huh? I had dozens of these in my logs every day, going back months. But I also had no complaints from people about queries failing. Strange.
So I wanted to track down what was causing these errors. I’ve got Query Store enabled, so my first thought was to start looking there. But the error in my thinking quickly became apparent. The error says SQL Server “could not produce a query plan.” I’m guessing that means I wouldn’t find anything in the Query Store.
So I turned to Extended Events and set up a session looking for error 8623. After running for a short while, I caught one of these errors. That gave me the host name of the computer that was submitting these complex queries. I narrowed my monitoring down to that server and that let me find a couple of queries causing the problems.
The machine in question was one that handles searches for our website. The server was submitting queries that looked like this:
That’s just beautiful. The statement actually continued on for who knows how long, but it was too long to fit in the extended events sql_text buffer.
Some research turned up this warning from Microsoft BOL:
Explicitly including an extremely large number of values (many thousands of values separated by commas) within the parentheses, in an IN clause can consume resources and return errors 8623 or 8632. To work around this problem, store the items in the IN list in a table, and use a SELECT subquery within an IN clause.
Looks like I found the problem. I actually counted the number of items in that IN statement. 1,077, but don’t hold me to that. I sneezed when counting and may have lost my place. There’s definitely enough to qualify as “an extremely large number,” I do believe.
So I contacted our devs and told them the problem. They said this code was generated by a third party app that uses entity framework to update our search indexes. They’ve added a task to move this functionality to an in-house developed stored procedure, but it will take a while to implement that change because it requires some application architecture changes.
So I’m stuck with my error logs filling with these. Bummer.
I know computer-generated SQL is not the most well-written code, but this is the first time I have ever seen some that doesn’t just perform poorly, but actually causes errors. Three cheers for AI!