I got an email from one of my developers regarding a process they had developed in-house. The process has been taking longer and longer to run and it had reached the point where the application was timing out while waiting for a response from the database. Some investigating revealed that the process was timing out after 30 seconds. This process was developed in .NET and the default timeout for .NET applications is 30 seconds, so at least we identified why the application was timing out.
The next step then was to look at the code that was being run and determine why the database was taking more than 30 seconds to return data. To make a long story short, there were stored procedures calling stored procedures calling views and the whole thing was basically a mess. But the root cause, believe it or not, was implicit conversions, mainly with dates. The views were joining several tables and the stored procedures were referencing several of the columns in WHERE clauses. In some of the tables, dates were stored as date datatypes, but in others they were stored as varchar datatypes. As a result, virtually every join required an implicit conversion and almost no WHERE clauses were SARGable.
A common way of troubleshooting performance issues is to look at the execution plan using SSMS. Unfortunately, implicit conversions are easily overlooked in an execution plan because they don’t have their own little symbol – you have to mouse over a symbol and read the pop up text to see them.
Let’s look at a simplified example. We have the following table:
For demonstration purposes, I’m not going to join to any other tables, but the concept is the same. Let’s look at this SELECT statement:
SELECT * FROM [dmPCOMBDaysNoHolidays] WHERE CONVERT(VARCHAR(5), YEAR(calendarDate)) = '2014'
If we execute this statement and include the execution plan, we get the following:

Nothing exciting there. Standard stuff. But let’s hover the mouse over the clustered index scan icon and look at the text that pops up:
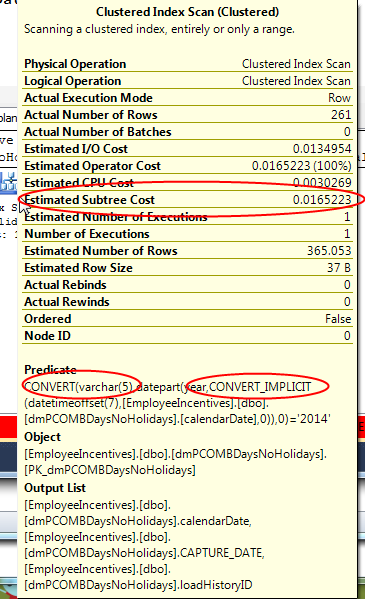
You can see two conversions – let’s look at them in reverse. The second is the implicit conversion that changes the varchar column from the table into a date datatype to feed into the YEAR function. Because the YEAR function returns an integer, we explicitly convert this into a varchar(5) to compare to ‘2014’, which is the first conversion listed. (Don’t ask me why it’s varchar(5) and not varchar(4). That’s just another example of how bad this code is.)
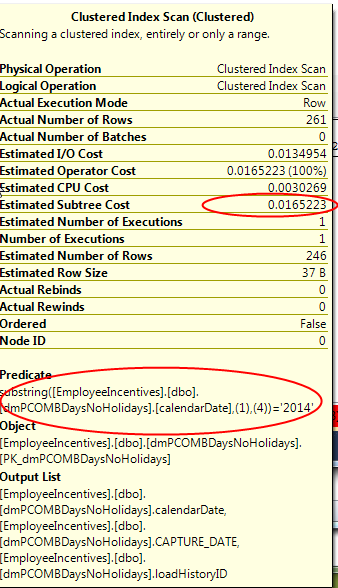
Note the subtree cost. We’ll come back to that.
Now let’s re-write this query and try to eliminate that explicit conversion. We can use this:
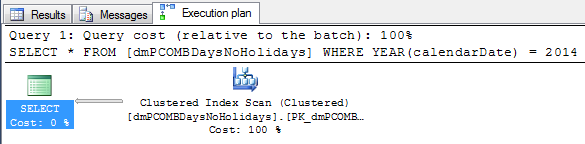
SELECT * FROM [dmPCOMBDaysNoHolidays] WHERE YEAR(calendarDate) = 2014
Because the YEAR function returns an integer, we can compare the result to the integer value of 2014, instead of the string value ‘2014’. Our execution plan looks exactly the same:
But the mouseover text now has some differences:
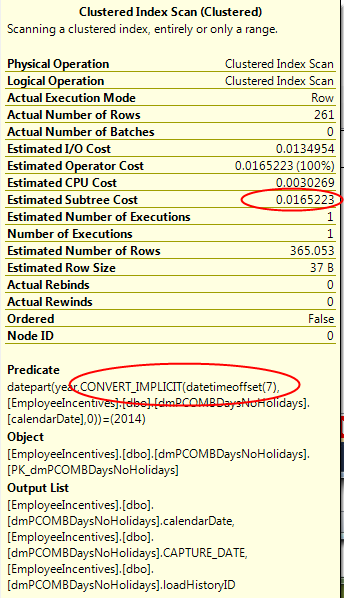
Our explicit conversion is gone – as expected since we were the ones who got rid of it. We still have the implicit conversion of the column data to a date datatype for use in the YEAR function. So we’re doing one less conversion, which means SQL Server has less work to do. You would expect the estimate subtree cost would drop. But, surprisingly, it did not. Hmm.
Now let’s make one more change. If we actually look at the data, we see it looks like this:
The data values all are in the format YYYY-MM-DD. Knowing this, we can now write our query as follows, keeping everything as character data:
SELECT * FROM [dmPCOMBDaysNoHolidays] WHERE LEFT(calendarDate,4) = '2014'
Again, the resulting execution plan looks identical to our other two:
Looking at the mouseover text, we see we no longer have any conversions at all. Yet, the subtree cost remains the same.
In summary, our original query did the following:
- Convert varchar datatype to a date datatype
- Run this value through the YEAR function, which returns an integer datatype
- Convert the integer back into a varchar for the comparison to the criteria
Because this is a non-SARGable query, these three steps have to be done for each and every row in the table.
Our re-written query does the following:
- Compares the leftmost 4 characters of the calendarDate field with the criteria
We’ve cut the work down by 66%. That’s an improvement, but it’s a rather small one. Unfortunately, without changing the database schema, it’s all we can do.
Now in these examples, the table only has a few thousand rows, so we’re not seeing changes in cost or noticeable changes in performance. However, in the actual application I was troubleshooting, these conversions were happening for multiple tables with hundreds of thousands of rows, in multiple places, in WHERE clauses, and on joining columns. It all added up to very slow performance.
Unfortunately, for situations like these, there is very little a DBA can do to dramatically improve performance. All of the WHERE clauses in these examples are non-SARGable and will require an index scan of all rows rather than an index seek of a subset of rows. To fix performance issues caused by this type of problem, the only answer is a code re-write, schema re-design, or, more likely, both
As a test, I reproduced the tables in the process using correct and consistent datatypes, created the same indexes on them, loaded the exact same data, and ran the queries (modified only to not perform all the no-longer necessary datatype conversions) against the new schema. Performance was improved by an order of magnitude. If you only looked at execution plans, it might look like the changes did not make any difference, but in reality, the difference was significant.
LEFT(calendarDate,4) = ‘2014’
All of the WHERE clauses in these examples are non-SARGable
Clearly calendarDate would benefit from being a DATE or DATETIME datatype :), but given a suitable index I think the following would be SARGable?
WHERE calendarDate >= '2014-01-01'
AND calendarDate <'2015-01-01'
Might be worth telling the DEVs that “yyyy-mm-dd” strings are ambiguous, depending on Language, and they need to use “yyyymmdd” if they want conversion to datetime, implicit or otherwise
SET language 'French'
GO
SELECT CONVERT(datetime, '2015-12-31')
Although the rules are different for DATE datatype and CONVERT(date, ‘2015-12-31’) seems to be treated as unambiguous
Sorry, all pedantic points.
Yes, those examples would also be SARGable. I would love to convert all the fields to date or datetime datatypes, but that was outside of my control as it would require the devs to make source code changes, which they did not have the time to do. Fortunately, we deal with only US dates, so our language settings shouldn’t hurt us, but that is one more thing to watch out for with dates.